数据湖存储格式Hudi原理与实践 优化数据分析与存储服务
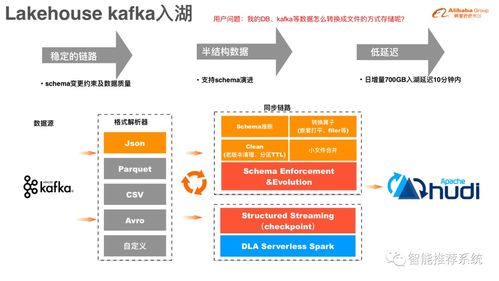
随着大数据技术的快速发展,数据湖已成为企业数据管理和分析的关键基础设施。Apache Hudi(Hadoop Upserts Deletes and Incrementals)作为一种高效的数据湖存储格式,通过支持增量数据处理、事务性保证和高效的更新删除操作,显著优化了数据存储与分析服务的性能。本文将深入探讨Hudi的原理,并结合实践案例,展示其在数据分析和存储服务中的应用价值。
Hudi的核心原理
Hudi的核心设计理念是提供一种可扩展的数据湖存储解决方案,支持近实时的数据摄入和处理。其工作原理主要基于以下几个方面:
- 表类型与存储格式:Hudi支持两种表类型:Copy-on-Write(COW)和Merge-on-Read(MOR)。COW表在写入时直接更新数据文件,适用于读多写少的场景;而MOR表通过将更新和删除操作记录到日志文件中,提升写入性能,同时支持高效的查询。Hudi使用列式存储格式(如Parquet)和行式日志文件(如Avro),实现数据的高效压缩和快速访问。
- 增量处理与事务性:Hudi通过时间线(Timeline)机制记录所有数据操作,包括提交、清理和压缩事件。这确保了数据的一致性,并支持增量查询,允许用户仅处理自上次查询以来变更的数据,从而减少计算资源消耗。事务性保证基于乐观并发控制,允许多个写入操作并行执行,同时通过版本控制和冲突解决机制维护数据完整性。
- 索引与数据管理:Hudi内置索引系统(如布隆过滤器索引),用于快速定位数据记录,支持高效的更新和删除操作。Hudi提供自动的数据清理、压缩和归档功能,帮助优化存储空间并提升查询性能。
Hudi的实践应用
在数据分析与存储服务中,Hudi已广泛应用于实时数据处理、数据仓库优化和机器学习等场景。以下为一些典型实践案例:
- 实时数据管道构建:在金融或电商领域,企业需要实时处理交易数据。使用Hudi,可以构建高效的流式数据管道,通过Kafka等消息队列摄入数据,并利用Hudi的增量处理能力,实现低延迟的数据更新和查询。例如,某电商平台使用Hudi处理用户行为数据,将数据湖中的更新操作延迟从小时级降至分钟级,提升了实时推荐系统的准确性。
- 数据湖与数据仓库集成:Hudi支持与Spark、Flink和Presto等计算引擎无缝集成,帮助企业将数据湖与现有数据仓库(如Hive或Snowflake)结合。通过Hudi的事务性特性,企业可以在数据湖中执行复杂的ETL作业,同时确保数据一致性。例如,一家物流公司使用Hudi管理运输数据,实现了数据湖与云上数据仓库的实时同步,优化了货物跟踪和库存分析服务。
- 成本与性能优化:Hudi的数据管理功能,如自动压缩和分区优化,帮助企业降低存储成本并提高查询效率。实践表明,采用Hudi后,企业可以减少冗余数据存储,并通过增量查询减少计算开销。例如,一家媒体公司使用Hudi处理日志数据,存储成本降低了30%,同时查询响应时间提升了50%。
总结与展望
Apache Hudi作为一种先进的数据湖存储格式,通过其独特的设计原理和灵活的实践应用,为数据分析和存储服务带来了显著改进。未来,随着云原生技术和AI驱动的数据管理发展,Hudi预计将进一步增强其实时处理能力和生态系统集成,成为企业数据基础设施的关键组件。对于希望优化数据湖架构的组织而言,深入理解Hudi的原理并积极实践,将有助于提升数据驱动决策的效率与可靠性。
如若转载,请注明出处:http://www.xspush.com/product/8.html
更新时间:2026-06-19 22:11:42









