Python在数据科学中的应用 数据加载、存储与文件格式及数据分析服务概述
Python在数据科学中的应用:数据加载、存储与文件格式及数据分析服务概述
在当今数据驱动的时代,Python凭借其强大的生态系统和简洁的语法,已成为数据科学领域最受欢迎的工具之一。本文将从数据加载与存储、文件格式选择以及数据分析服务三个核心层面,探讨Python在数据处理流程中的关键作用。
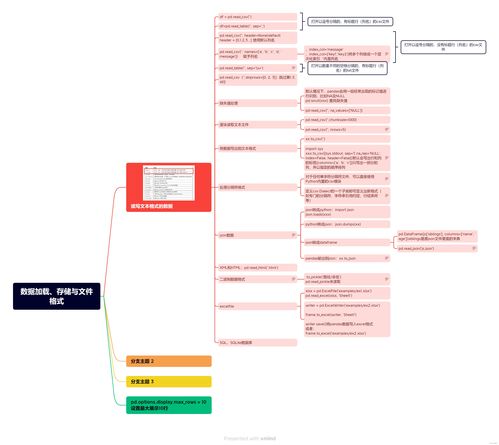
一、数据加载与存储
数据加载是数据分析的第一步。Python通过多种库支持从各种来源高效读取数据:
- 内置文件操作:使用
open()函数可处理文本文件,但更适合结构化数据的是专用库。
2. Pandas库:作为数据分析的核心工具,Pandas提供了read<em>csv()、read</em>excel()、read<em>json()等函数,支持从CSV、Excel、JSON等多种格式加载数据。例如:
`python
import pandas as pd
df = pd.readcsv('data.csv')
`
- 数据库连接:通过
sqlalchemy或pymysql等库,可从MySQL、PostgreSQL等关系型数据库加载数据;pymongo支持MongoDB等NoSQL数据库。
- API与网络数据:
requests库可用于从Web API获取JSON或XML格式数据。
数据存储同样重要,Pandas的to<em>csv()、to</em>excel()等方法可将处理后的数据保存到文件,而数据库操作库则支持将数据持久化到数据库中。
二、文件格式的选择与处理
选择合适的文件格式能提升数据处理的效率和性能。常见格式包括:
- CSV(逗号分隔值):通用性强,但缺乏数据类型定义,不适合大型数据集。
- Excel文件:适合商业场景,但处理速度较慢,且依赖外部库。
- JSON:适用于嵌套数据结构,常用于Web数据交换。
- HDF5:支持大型科学数据集,通过
pandas.HDFStore实现高效存储。
- Parquet与Feather:列式存储格式,Parquet兼容Hadoop生态系统,Feather提供更快的读写速度。
选择格式时需考虑数据大小、结构、读写速度及跨平台兼容性。例如,大数据场景下Parquet往往优于CSV。
三、数据分析和存储服务
随着数据规模增长,本地处理可能遇到瓶颈,此时可借助云服务:
- 云存储服务:如AWS S3、Google Cloud Storage,Python的
boto3库支持直接读写S3数据,实现无限扩展的存储。
- 数据分析平台:Databricks、Google Colab等提供基于Python的云端分析环境,集成数据处理和机器学习工具。
- 数据库即服务:AWS RDS、MongoDB Atlas等托管数据库服务,可通过Python连接进行高效数据管理。
- 自动化管道:使用Apache Airflow或Prefect等工具,可调度Python脚本实现数据加载、转换和存储的自动化。
四、实践建议
- 对于小型项目,Pandas结合CSV或Excel足矣;大型数据应考虑Parquet格式和云存储。
- 使用虚拟环境(如conda)管理依赖,确保库版本兼容。
- 编写可复用的数据加载函数,提升代码维护性。
Python通过丰富的库和服务集成,为数据加载、存储和分析提供了灵活高效的解决方案。掌握这些工具,将帮助数据科学家更好地应对实际挑战,从数据中提取有价值的信息。
如若转载,请注明出处:http://www.xspush.com/product/61.html
更新时间:2026-02-24 02:30:24